Introduction:
The bounded knapsack problem is a well known computer science problem which falls under the group of NP (Non deterministic Polynomial time) problems. This problem has been studied for over a century with some of the earliest known works dating back to 1897. It is related to the task of resource allocation and has many applications such as finding the least wasteful way to cut raw material and selection of investments and portfolios.
Description:
You are given a knapsack which can hold a limited weight (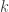 ). You must choose from a variety of items with different weights (
). You must choose from a variety of items with different weights ( ) and values (
) and values ( ). The goal is to maximize the value of the items held in the knapsack without exceeding the knapsack weight limit (). Note* You are only allowed to take one of each item and you cannot take a fraction of an item.
). The goal is to maximize the value of the items held in the knapsack without exceeding the knapsack weight limit (). Note* You are only allowed to take one of each item and you cannot take a fraction of an item.

Let 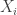 be an item within the set of all items
be an item within the set of all items  that have a weight and value
that have a weight and value
Maximize 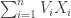
While  and
and 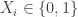
1) Decision problem : Can the value ( ) be achieved without exceeding the maximum weight allowed ()?
) be achieved without exceeding the maximum weight allowed ()?
2) Optimization problem : What is the optimal value that can be achieved without exceeding the maximum weight allowed ()?
Computational Complexity:
The knapsack problem falls under the NP set of problems. It is non deterministic since there are multiple possible paths that have to be searched to find a solution – it is not just a linear search with simple state transitions. It is also considered polynomial time since an algorithm that takes  time or less has not been found, where n is the amount of items in the set and q is a constant. Depending on how the knapsack problem is presented, it can be considered NP-Complete or NP-Hard.
time or less has not been found, where n is the amount of items in the set and q is a constant. Depending on how the knapsack problem is presented, it can be considered NP-Complete or NP-Hard.
1) Decision Problem : Validating that the value () be achieved without exceeding the maximum weight () is considered NP-Complete.
Why is it NP-Complete? To verify that a certain value can be achieved requires that we iterate over the different permutations of items until we reach a value that satisfies the conditions. We may have to iterate over all permutations of the items but that is not always the case.
2) Optimization problem : Finding the optimal value that can be achieved without exceeding the maximum weight allowed () is considered to be NP-Hard.
Why is it NP-Hard? To find the optimal value that can be achieved requires that we iterate over all permutations of the items. It is at least as difficult as the optimization problem. There is no known algorithm which is polynomial time or less that can validate if a given solution is optimal.
Test/Example Cases:
I have chosen several test cases to benchmark the performance of each algorithm. The test cases file (Knapsack_test.txt) is provided in the link below. The format of the file is as follows :
The first line contains an integer ( ) representing the amount of test cases in the file. Then the following lines will contain groups of test cases where the fist line of a test case will have the number of items available (
) representing the amount of test cases in the file. Then the following lines will contain groups of test cases where the fist line of a test case will have the number of items available (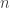 ) with the max weight of the knapsack (
) with the max weight of the knapsack ( ). The second line in the test case will have the weight of each item (
). The second line in the test case will have the weight of each item ( ) and the third line in the test case will have the value of each item (
) and the third line in the test case will have the value of each item ( ).
).
//Number of cases
 //Case 1 amount of items , max weight
//Case 1 amount of items , max weight
 //Case 1 weight of each item
//Case 1 weight of each item
 //Case 1 value of each item
//Case 1 value of each item
//Case 2 amount of items , max weight
//Case 2 weight of each item
//Case 2 value of each item
… and so on
Analysis/Solutions:
The Greedy algorithm
The greedy algorithm will choose the best possible option for the parameter it is trying to optimize. There are multiple greedy algorithms that can be implemented for this problem. You can choose to optimize either the value or weight parameters or the value per weight. Advantages of greedy algorithms include being very fast and quick to implement. The disadvantage of a greedy algorithm is that the quality of the results may not be correct depending on the input and it will not work well on complex problems. I will show a greedy algorithm trying to use the best value per weight of the items and how it fails.
The steps of a greedy approach :
- Choose the item with the greatest value per weight and check that the weight of the item is less than the maximum weight. MAX (
 ) < .
) < .
- Add the item to the knapsack and remove it from the set of items.
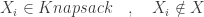 .
.
- Update the max weight to show that an item was added.

- Repeat steps 1 to 3 until there are no remaining items that can fit in the knapsack. while(
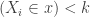 ) : repeat steps 1 – 3.
) : repeat steps 1 – 3.
So lets examine an example case of how the algorithm works :


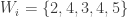


The greedy algorithm seems to work correctly in this case where it achieves a maximum value of 31. During the first iteration, 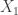 is chosen since it has the highest value per weight (
is chosen since it has the highest value per weight ( ). During the second iteration,
). During the second iteration,  is chosen since it has the highest value per weight (
is chosen since it has the highest value per weight (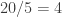 ) of the remaining set. During the third iteration,
) of the remaining set. During the third iteration,  is chosen because it is the only item which has a weight that can fit in the knapsack.
is chosen because it is the only item which has a weight that can fit in the knapsack.
Now lets look at a case where the greedy algorithm will fail :


In this case the greedy algorithm could not find the optimal solution. The correct solution would be to select items 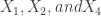 which would add up to a total value of 40. As you can see, the greedy algorithm can find a solution quickly but it does not guarantee that the solution is optimal.
which would add up to a total value of 40. As you can see, the greedy algorithm can find a solution quickly but it does not guarantee that the solution is optimal.
Dynamic Programming:
Dynamic programming is a bottom up approach to solving problems where you start by solving the smallest elements of the problem. The smallest element of the knapsack problem is to select one item at a time and fit it in the knapsack and then add a heavier item to the knapsack until it is full. We will have to make a table and calculate the most efficient ordering of items for every weight (1 to k) using the following algorithm. We will denote the series of different knapsack weights as  .
.
Note** To simplify the algorithm, you must first sort the set of items by weight from least to greatest. Items of the same weight are sorted by value from greatest to least.
- Begin with a table of rows and columns where is the max weight of the knapsack and is the amount of items to choose from.
- Initialize the first column with the value of the lightest item () for all weights from 1 to where the item weighs less than the knapsack max weight.
- Compute the optimal ordering of the next item by first checking if it can fit in the knapsack and then check if it holds a value greater than or equal to the max value calculated for the previous items (
 ) at the same knapsack weight.
) at the same knapsack weight.
- If the value is higher, check if there is any remaining space in the knapsack for additional items.
- If there is additional space, look up the optimal value in the max values table for the previous items () at the weight difference (
 ). Add this value to the value of the current item () and set this as your max value.
). Add this value to the value of the current item () and set this as your max value.
- If the item holds a lower value than the max value calculated for the previous items (), it may still have an optimal ordering which can give a max value.
- We have to assume that the current item () is added to the knapsack initially.
- Next we will look up the optimal value arrangement of the previous items() at the weight difference (). Add this value to the value of the current item () and check if it is greater than the max value computed for the current knapsack weight ()
- If the max value calculated with the current item is not greater than or equal to the previous max value entries, we will keep the previous entry value.
- Repeat steps 3 to 5 until you have calculated a full table. The last entry in the table is the optimal value that can be achieved.
Lets look at an example:
You are given a function for the weights and values and the knapsack weight. Each cell contains the max value that is possible for the given max weight () and items available (). In each cell, I have put the ordering of the items followed by the optimal value shown in red.

I have provided a C++ code sample of how to use dynamic programming to solve the knapsack problem.
</pre>
<pre>#include
#define ITEM_COUNT 5 //This is how many items are available
#define K_MAX 10 //This is the max weight of the knapsack
/**
* Items have a value and weight
*/
struct Item{
int value;
int weight;
};
/**
* This function is used to print a matrix
* @param mat This is a pointer to the matrix
* @param rows This is the length of the X dimension
* @param columns This is the length of the Y dimension
*/
template
void printMatrix(int (&mat)[rows][columns]){
std::cout << "Printing matrix of " << rows << " by " << columns <<" dimensions" << "\n";
for(size_t i = 0; i < rows+1; i++){
for(size_t j=0; j < columns+1; j++){
if(i == 0){
std::cout << j << " ";
}
else if(j == 0){
std::cout << i << " ";
}
else {
std::cout << mat[i - 1][j - 1] << " ";
}
}
std::cout << "\n";
}
}
template
void updateMaxValues(int (&max_values)[rows][columns], Item (&items)[item_count], int item_counter, int weight_counter,int k_weight){
//Check if the item can fit in the knapsack
if(items[item_counter].weight <= k_weight){ //Set the max value on the first iteration if(item_counter == 0) { max_values[weight_counter][item_counter] = items[item_counter].value; return; } //Check if the current item has a better value than the max value entry else if(items[item_counter].value >= max_values[weight_counter][item_counter-1]){
//Set the new max value to the value of the current item
max_values[weight_counter][item_counter] = items[item_counter].value;
//Check if there is any remaining space in the knapsack
if(items[item_counter].weight < k_weight){ //If we have some remaining space, look up the optimal value arrangement of items from previous entries int remaining_space = k_weight-items[item_counter].weight; //Add the optimal value arrangement of smaller items to the value of the current entry max_values[weight_counter][item_counter] += max_values[remaining_space-1][item_counter-1]; } return; }//Check if we can find another optimal weight arrangement based on the previous entries else{ //Assume that we put the current item in the knapsac first and calculate the remaining weight int remaining_space = k_weight - items[item_counter].weight; if(remaining_space > 0){
//Look up the optimal value possible using the remaining weight and items and add that to the current value
int max_value_possible = max_values[remaining_space-1][item_counter-1] + items[item_counter].value;
if(max_value_possible >= max_values[weight_counter][item_counter-1]){
max_values[weight_counter][item_counter] = max_value_possible;
return;
}
}
//Set the max value possible to the previous entry if a max value could not be found with the current item
max_values[weight_counter][item_counter] = max_values[weight_counter][item_counter - 1];
return;
}
}
else {
//There is no item that can fit in this space
if(item_counter == 0) {
return;
}
//Set the max value possible to the previous entry if a max value could not be found with the current item
max_values[weight_counter][item_counter] = max_values[weight_counter][item_counter - 1];
}
}
int main() {
std::cout << "This is an example of dynamic programming to solve the 1/0 knapsac problem" << std::endl;
//These are the items available sorted by weight and value
Item items[ITEM_COUNT] = {{12,2},{1,3},{16,4},{12,4},{25,5}};
int max_values[K_MAX][ITEM_COUNT] = {0};
//Compute the max value possible for the items available at all knapsack weights up to K_MAX
for(size_t item_counter = 0; item_counter < ITEM_COUNT; item_counter++){
for(int weight_counter = 0; weight_counter < K_MAX; weight_counter++) {
updateMaxValues(max_values, items, item_counter, weight_counter, weight_counter+1);
}
}
printMatrix(max_values);
return 0;
}</pre>
<pre>
The video below shows the output of the code above when running. The first column in red is the different knapsack weights and the first row in red is the items that are made available for choosing.